大(dà) 创 实 验 室
【前沿】从算法到硬件,一(yī)文读懂2019年 AI如何(hé)演进
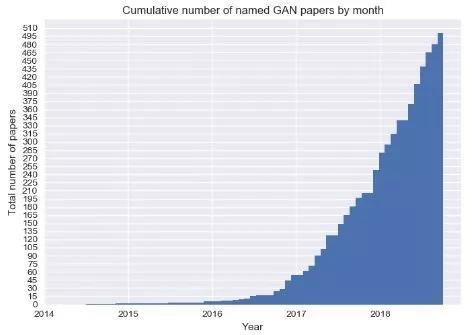
Medium的一位专(zhuān)栏作者为(wéi)此撰文概括(kuò)了过去一年中人工智(zhì)能领(lǐng)域(yù)的一些模式,并试图勾勒出其中的某些趋势。注(zhù)意,这篇总结(jié)是以(yǐ)美国(guó)的(de)发展为中心展开,以下(xià)是文章全文: 算法 毫无疑问,算法话语权由深(shēn)度神经网络(DNN)主导。 当然,你(nǐ)可能会(huì)听说有人在这里(lǐ)或那里部署了(le)一个“经典的”机(jī)器学习模型(比如梯度提升(shēng)树(shù)或(huò)多臂(bì)老虎机),并声称(chēng)这是每个(gè)人唯一需要的(de)东西。有人宣称,深(shēn)度学习(xí)正处于垂死(sǐ)挣扎(zhā)中。甚至连顶级的研究人员也在质疑一些深度神经网络( DNN) 架构的(de)效率(lǜ)和抗变换性。 但是,不管你喜欢与(yǔ)否,DNN无处不在: 自动驾驶汽车、自然(rán)语言系统、机器人——所有(yǒu)你能(néng)想到的皆(jiē)是(shì)如此。 在自然语言处(chù)理(lǐ)、生成式对抗网络和深度增强学(xué)习中,DNN取得的飞跃尤为明显。 Deep NLP: BERT以及其他 尽管在2018年之前,文本(běn)使用DNN(比如word2vec、GLOVE和基于LSTM的模型)已经取得(dé)了一些突破,但缺少一个关键的概念元素:迁(qiān)移学(xué)习。 也就是说,使(shǐ)用大量公开可(kě)用的数(shù)据(jù)对模型进行训练,然后根(gēn)据你正在处理的特定数据集对其(qí)进行(háng)“微调”。在计算机视(shì)觉中,利用在著(zhe)名的 ImageNet 数据集(jí)上发现的(de)模式来(lái)解决特定的(de)问题(tí),通常是一种(zhǒng)解决方案。 问题是(shì),用于(yú)迁移学习(xí)的技巧(qiǎo)并不能很好地应用于自然语言(yán)处(chù)理(NLP)问题。在某种(zhǒng)意(yì)义上(shàng),像 word2vec 这样的预(yù)先训练的嵌入正在弥(mí)补这一(yī)点,但它们只能应(yīng)用于单个单词级别,无法捕捉到(dào)语(yǔ)言的高级结构(gòu)。 然而,在2018年,这种情况发生(shēng)了变化。 ELMo,情境(jìng)化嵌入成为提(tí)高 NLP 迁移(yí)学习的第一个(gè)重(chóng)要(yào)步(bù)骤。ULMFiT 甚至更(gèng)进一步(bù): 由于不满意嵌入式的语义捕捉能(néng)力,作者找到(dào)了一(yī)种为整个模型进行迁(qiān)移学习的方法。 但(dàn)最有(yǒu)趣的进步无疑是BERT的引入。通过让(ràng)语(yǔ)言(yán)模型从(cóng)英文(wén)维基百科的全部文章中(zhōng)进行(háng)学习,这个团队能够在11个 NLP 任务(wù)中取得(dé)最高水准的结果——这是一个壮举!更妙的是,它开源了。所(suǒ)以(yǐ),你可以把这一突破应用到自己的研究问题(tí)上。 生(shēng)成(chéng)式对抗网(wǎng)络(GAN)的多面性 CPU的速度不会再呈(chéng)现指数级的增长,但(dàn)是生成式对抗网(wǎng)络(GAN)的学(xué)术(shù)论文(wén)数量肯定会(huì)继续增长(zhǎng)。GAN多年来一(yī)直是学术界(jiè)的宠儿。然而(ér),其在现实生活(huó)中(zhōng)的应用似乎(hū)很少,而且(qiě)这一点在(zài)2018年几乎没有改变。但是GAN仍然有着惊人的潜力等待着我们去实现。
目前出(chū)现了一(yī)种新的方法,即逐步(bù)增加生成式对抗网络: 使生成器在整个(gè)训练过程中逐步提高其输出的分辨率。很多令人印象深刻(kè)的论文(wén)都使用了这种方(fāng)法,其中有一篇采(cǎi)用了风(fēng)格转移技术来生成逼真的照片(piàn)。有(yǒu)多逼真?你来告诉我: 这些照(zhào)片中哪一(yī)张是真人?
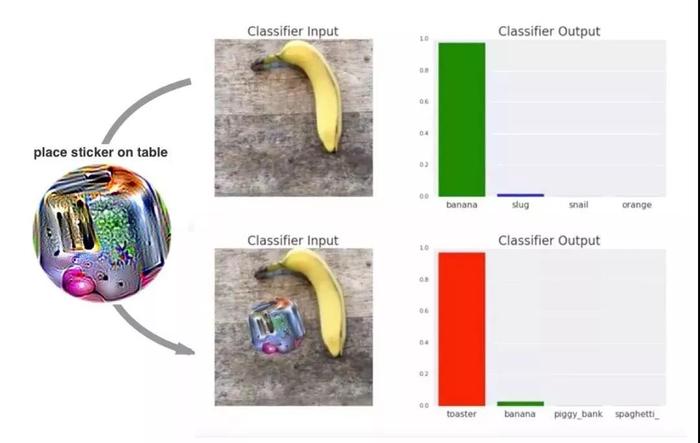
这个问题有陷阱:以上皆不是。 然而,GAN是如何工作的,以(yǐ)及它为什么会起效呢?我们(men)对此还缺乏深入的了解,但是(shì)我(wǒ)们正在采取一些重要的措施(shī): 麻省(shěng)理工学院的一个团队已经对这个问题进行了高质(zhì)量(liàng)的研究。 另一个有趣的进(jìn)展是“对抗补丁“,从技术上来说它并非是(shì)一个生成式(shì)对抗网络。 它同时使用黑盒(基本上不考虑(lǜ)神经网络的内(nèi)部(bù)状(zhuàng)态)和白盒(hé)方法来制作一个“补丁”,可以骗过一(yī)个基(jī)于 CNN的分类(lèi)器。 从(cóng)而得(dé)出一个重(chóng)要的结果:它引导我们(men)更好地了(le)解深度神经网络(luò)如何工(gōng)作(zuò),以及我们距离获得人类级别(bié)的(de)概(gài)念认知还有多远。
你(nǐ)能区(qū)分香蕉和烤(kǎo)面包机(jī)吗(ma)?人工智能(néng)仍然不能。 强化(huà)学习(xí)(RL) 自从2016年 AlphaGo 击败(bài)李世石后,强化学习就一直是公众关注的焦点。 在(zài)训练(liàn)中,强化学习依赖于“奖励”信号(hào),即(jí)对(duì)其在最后一次尝(cháng)试中表现的(de)评(píng)分(fèn)。电脑游戏提供了一(yī)个与现(xiàn)实生活相反的自然环境,让这种信(xìn)号随时可用。因此(cǐ),RL研究(jiū)的所(suǒ)有注意力都放在了教 AI玩雅达利游戏上。 谈到它们的新发明 DeepMind,AlphaStar又成了新(xīn)闻。这种新模(mó)式(shì)击败了星际争霸 II的顶级职业选手之一。星际争霸比(bǐ)国际象棋和(hé)围棋(qí)复(fù)杂得多,与大多数棋(qí)类游戏不同,星际争霸(bà)有巨大的动作空间和隐藏在玩家身上的重要信息。这次胜(shèng)利对整个领域来说,都是一次非常重要的飞跃。 在RL这个领域,另一(yī)个重要(yào)角色OpenAI也没有闲着。让它们(men)声名鹊起的是(shì)OpenAI Five,这个系统在2018年8月(yuè)击(jī)败(bài)了(le)Dota 2这个极其复杂的电子(zǐ)竞技游戏中99.95%的玩家。 尽管 OpenAI 已(yǐ)经对电脑游(yóu)戏给予了很多关注,但是他们并没有忽视 RL 真正的潜在应(yīng)用领域: 机(jī)器(qì)人。 在现实世界中,一个人能够(gòu)给予机器人的(de)反馈是非常稀少且昂贵的:在(zài)你的 R2-D2(电(diàn)影中(zhōng)的虚拟(nǐ)机器人)尝(cháng)试走出(chū)第一“步”时,你基本上(shàng)需要一个人类保姆来(lái)照(zhào)看它。你(nǐ)需要数以百万计的数(shù)据点。 为了弥合这一(yī)差距(jù),最新(xīn)的趋势是学(xué)会模(mó)拟一个(gè)环境,同时(shí)并行地运行大(dà)量(liàng)场景以教授机器人基本(běn)技能(néng),然后再(zài)转向现实世界(jiè)。OpenAI和(hé)Google都在(zài)研究这(zhè)种方法。 荣誉奖:Deepfakes Deepfakes指(zhǐ)一些伪造的图像或视频,(通(tōng)常(cháng))展示(shì)某个公(gōng)众人物正在(zài)做或说一些他(tā)们(men)从未做过或说过(guò)的事情。在“目标”人物大量镜头的基础上训练一个生成式对抗网络(luò),然后在其中生(shēng)成包(bāo)含所(suǒ)需动作(zuò)的(de)新媒体——deepfakes就(jiù)是这样创建的(de)。 2018年1月发布的名为FakeApp的桌面应用程序(xù),可以让所有拥有计算机科学(xué)知识(shí)的(de)人(rén)和对此(cǐ)一无所知的人都能创建deepfakes。虽然它制作的视频(pín)很容(róng)易被人看(kàn)出来是假(jiǎ)的,但这项技术已经(jīng)取得了长足的进(jìn)步(bù)。
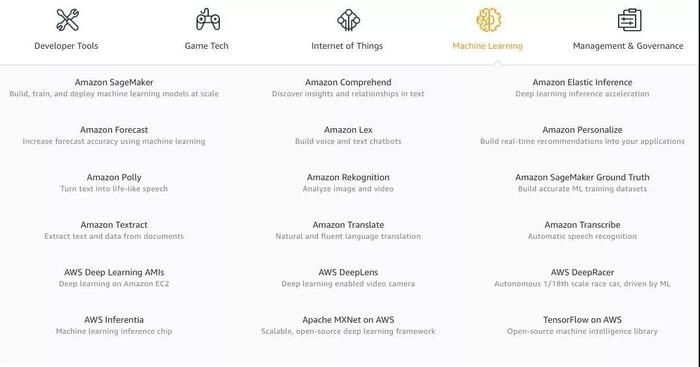
TensorFlow与PyTorch 目(mù)前,我们(men)拥有很多深(shēn)度学习(xí)框架。这(zhè)个领域是广阔的(de),这种多样性表面上看是(shì)有意义的。但实(shí)际(jì)上,最近大多(duō)数(shù)人都(dōu)在使用Tensorflow或PyTorch。如果你关心可靠性、易于部署性和(hé)模型(xíng)重载等SREs 通常(cháng)关心(xīn)的问题,那么你(nǐ)可能(néng)会选择 Tensorflow。如果你正在写(xiě)一篇研究论文(wén),而且不在谷歌工作,那么(me)你很可能使用PyTorch。 ML作为一种服务(wù)随(suí)处可见 今年,我们看到(dào)了(le)更多的人工智能解(jiě)决方案,它们被一个未获得斯坦福大学机器学(xué)习博士学位的软(ruǎn)件工程(chéng)师打包成一个供消费的 API。Google Cloud和Azure都改进了(le)旧(jiù)服务,并(bìng)且增(zēng)加了新服务。AWS机(jī)器学习服务列表开始看起来十分令人生(shēng)畏。
天啊,AWS的服务很快就会多(duō)到需要(yào)两级目录层次结(jié)构来展示了。 尽管这(zhè)种狂热现象已经冷却了一些(xiē),但(dàn)还是有很多创业(yè)公(gōng)司发出了挑战。每个人都承诺了模型(xíng)训练的(de)速度、推理过程中的易用性和惊人的模型(xíng)性能。 只要输入你的信用卡信息,上传你的数据,给模型一些时间去(qù)训练或者微调,调用 REST (或者,给更(gèng)有(yǒu)前瞻(zhān)性的创业公司GraphQL)的 API,就可以成为人工智能(néng)方面的(de)大师,甚至不(bú)需要搞清楚(chǔ)“随机失(shī)活(dropout)”是(shì)什么。 有了这(zhè)么多的选择,为什么还有人会费心自己(jǐ)建造模型(xíng)和基础设施呢?实际上(shàng),现成的 MLaaS 产品在80% 的(de)实用案例中表现得非(fēi)常(cháng)好。如果(guǒ)你希(xī)望(wàng)剩下的20% 也能(néng)正常工作,那就没那么(me)幸运了: 你不仅不能真正地选(xuǎn)择(zé)模型,甚至不能(néng)控(kòng)制超(chāo)参数。或者,如果(guǒ)你需要(yào)在云的舒适区之外的某个地方进行推断——一般情况下都做不(bú)到。这就是代价。 荣誉奖:AutoML和AI Hub 今年推(tuī)出(chū)的(de)两项特别有趣(qù)的服务均(jun1)由谷歌发布。 首先,Google Cloud AutoML是(shì)一套(tào)定(dìng)制(zhì)的 NLP 和计算(suàn)机视觉模型培训(xùn)产品。 这(zhè)是(shì)什么意思(sī)?汽车(chē)设计(jì)师通过自动微调(diào)几个预先训练的模型,并选(xuǎn)择(zé)其中最好的那(nà)个,从而解决(jué)了模型定制问题。这(zhè)意味着你很可能不(bú)需要自己去定制模型。 当然(rán),如果你想(xiǎng)做一些真正新鲜或(huò)不同的东西,那么这个服务并(bìng)不(bú)适合你。但是,谷歌在大量专(zhuān)有数据的(de)基(jī)础上预先(xiān)训练其模型,这是(shì)一个附带的好处。想(xiǎng)想所有关于猫(māo)的照片,它们一定(dìng)比 Imagenet 更具推广性(xìng)! 第二(èr),AI Hub 和 TensorFlow Hub。在这(zhè)两者出现之前,重(chóng)复使用某人的(de)模型确(què)实(shí)是件苦差事。基于 GitHub 的(de)随机代码很少能用,通常记(jì)录得很差,而且(qiě)一般来说,处理起来并不愉快。还有预先训练的迁移(yí)学习权(quán)重……这么说(shuō)吧,你甚(shèn)至(zhì)不想(xiǎng)尝试(shì)把它们用于工(gōng)作(zuò)中。 这正(zhèng)是TF Hub想要(yào)解决的问题(tí): 它(tā)是一个(gè)可(kě)靠的、有组织的模型存储(chǔ)库,你可(kě)以对其进行微调或构(gòu)建。只要(yào)加入几行代码——TF Hub 客户端就可以从谷(gǔ)歌的服务器上(shàng)获取代码和相应(yīng)的权重——然后(hòu),哇哦,它就可以(yǐ)正常工作了! Ai Hub 更进一步:它允许你共享整个ML管道,而不仅仅是模(mó)型!它仍(réng)然处于 alpha 测试阶(jiē)段,但如果(guǒ)你明白(bái)我的意思的话,它已(yǐ)经比一个(gè)连最新(xīn)的文件(jiàn)也是“3年前才修改(gǎi)”的随机存储库要好得多(duō)。 硬(yìng)件 Nvidia(英(yīng)伟达(dá)) 如果你在2018年(nián)认真研究过ML,尤其是(shì)DNN,那(nà)么你就曾(céng)用(yòng)过(guò)一个(或多个)GPU。因此(cǐ),GPU的领头羊在这一年里都非常忙碌。 随(suí)着加(jiā)密(mì)狂潮的冷却和随后的股价(jià)暴跌,Nvidia发布了基于图灵(líng)架构的全新(xīn)一代消费级卡。新卡仅使用了2017年发布的(de)基于Volta芯片的专业卡,且包含了被称为Tensor Cores的新的高速矩阵乘法(fǎ)硬件。矩(jǔ)阵乘法是DNN运行方式的核心,因此加快这些运算将大大提高新GPU上神经网(wǎng)络(luò)训练的速度。 对(duì)于(yú)那些对“小”和“慢”的游戏GPU不满(mǎn)意的人来说,Nvidia更新了他们的“超级计算平(píng)台”。 DGX-2具有多达(dá)16块Tesla V,用于FP16操作的(de)480 TFLOP(480万亿(yì)次浮(fú)点运(yùn)算),真可谓是一款“怪物”盒子(zǐ)。而其价(jià)格也(yě)更新了,高(gāo)达(dá)40万美元。 此外,自动硬件也得(dé)到(dào)了更新。Jetson AGX Xavier是(shì)Nvidia希望能为下一代(dài)自动驾驶(shǐ)汽车提供动力(lì)的一个模块。八核CPU、视觉加速器以及深(shēn)度学习加速器,这些都是日益增长的自动驾驶行业所需的(de)。 在(zài)一个有趣的开(kāi)发项目中,Nvidia为他们(men)的游(yóu)戏卡推(tuī)出了基于DNN的一种功能:深(shēn)度学习超级取样(Deep Learning Super Sampling)。其想法是去(qù)替换抗锯齿(chǐ),目前主要通过先渲染分辨(biàn)率高于(yú)所需(例如4倍)的图片然后(hòu)再将其(qí)缩放到本(běn)机(jī)监(jiān)视器分辨率来(lái)完成(chéng)。 现在(zài),Nvidia允许开发人(rén)员在发布游戏之前以极高的质量去训练图像转换模型。然后(hòu),使(shǐ)用(yòng)预先训练的模型将(jiāng)游戏发送(sòng)给最终用户。在游戏过程中,图形通(tōng)过该模型来(lái)运作以提高图像质量,而不会(huì)产生旧式抗锯齿的(de)成本。 Intel英特尔 英特尔在2018年绝对不是人工智能硬件领域的开(kāi)拓(tuò)者,但(dàn)似(sì)乎他们希(xī)望改变这一点。 令人惊讶的是(shì),英特尔的大多数动作(zuò)都发(fā)生在(zài)软件领域(yù)。英特尔正在努力使其(qí)现有和即(jí)将推出的硬件更(gèng)加适(shì)合开发人员。考虑到这一点,他(tā)们发布了一对(既令人(rén)惊(jīng)讶又有(yǒu)竞争力的)工具(jù)包:OpenVINO和nGraph。 他们(men)更新了自(zì)己的神经计算棒:一(yī)个小(xiǎo)型(xíng)USB设(shè)备(bèi),可以(yǐ)加(jiā)速任何带USB端口的DNN,甚至是Raspberry Pi。 有关英特(tè)尔独立GPU的传闻变得越来越错综(zōng)复杂。虽(suī)然这一传闻(wén)持续流传,但(dàn)新设备对DNN训练的适用(yòng)性仍有待(dài)观察。绝对适用于深度学(xué)习的是传闻中的专业深度学习卡,它们的代号为Spring Hill和(hé)Spring Crest。而后者基于(yú)初创(chuàng)公司(sī)Nervana(英(yīng)特尔(ěr)几年前(qián)已(yǐ)将(jiāng)其收购)的技(jì)术。 寻常(和不常见)的定制硬件 谷歌推出了他(tā)们的第三代TPU:基于ASIC的DNN专用加速器,具(jù)有惊人的128Gb HMB内存。256个这(zhè)样的设备组装成一个(gè)具(jù)有超过每秒100千兆次性(xìng)能的集合(hé)体。谷歌(gē)今年不再仅(jǐn)凭这些设(shè)备来挑逗世界的其他玩家了,而是通过Google Cloud向公众提供TPU。
在类似的、但(dàn)主要针对推(tuī)理应用(yòng)程序的项目中,亚马逊已经部署了AWS Inferentia:一种更便宜、更有(yǒu)效的在生产中(zhōng)运(yùn)行模型的方式。 谷歌还宣布了Edge TPU项目:这(zhè)个(gè)芯片(piàn)很小:10个(gè)芯片加起来才(cái)有一美分硬币的大(dà)小。与此同时,它能做到在实时视频上运(yùn)行DNN,并且几乎不消(xiāo)耗任何能量(liàng),这就足够了。 一个有趣的潜在新玩(wán)家(jiā)是Graphcore。这家英国公司已经筹(chóu)集了3.1亿美元,并在2018年推出了他们的第一款产品GC2芯(xīn)片。根据基准测试,GC2在进行推理时碾压了顶级(jí)Nvidia服务器GPU卡,同时消耗(hào)的功(gōng)率显(xiǎn)着降低。 荣(róng)誉奖(jiǎng):AWS Deep Racer 亚马逊推出了一款小型自动驾驶汽车DeepRacer,以及(jí)一个赛车联盟。这完全出人(rén)意料,但也有点像他们之前(qián)推出(chū)DeepLens时的情况。这款400美元(yuán)的汽车配备了Atom处理器,400万像素摄像头,wifi,几(jǐ)个USB端口,以及可运行数小时的充足电(diàn)量。 自动驾(jià)驶模型(xíng)可以使用完(wán)全(quán)在云端的3D模拟环境进行训练,然后直(zhí)接部(bù)署到这款车上。如果你一直梦想着建造自己的自动驾驶汽(qì)车,那么亚(yà)马(mǎ)逊的这款车就能让你如(rú)愿(yuàn),而不必再去自己(jǐ)创立受到VC支持的公司了。 接下来还有什么?重点会转向决策智能(néng) 既(jì)然(rán)算法、基础(chǔ)设施和硬件等让AI变得有用的因素都比以往任何时候要更好(hǎo),企业于是意识到开(kāi)始(shǐ)应用AI的最大(dà)绊脚石在于其(qí)实(shí)际性层(céng)面:你如何将AI从想法阶段落实(shí)到有效、安全(quán)又可靠的生(shēng)产系统中? 应用AI或应(yīng)用机器学习(ML),也称为(wéi)决策智能,是为现实世界问(wèn)题创建AI解决方案的科学。虽然(rán)过(guò)去我们把(bǎ)重点放在算法背后的科学上,但未来(lái)我们应该对(duì)该领域(yù)的端到端应(yīng)用给(gěi)予更加平等的关注。 人工智(zhì)能在促进(jìn)就业方(fāng)面功大于(yú)过 “人工智(zhì)能会拿走我(wǒ)们所有的(de)工(gōng)作”是媒体一直反复宣扬(yáng)的主题,也(yě)是蓝领和白领共(gòng)同(tóng)的恐惧。而且从表面上看,这似乎是一个合理(lǐ)的预(yù)测。但到(dào)目(mù)前为止,情(qíng)况恰恰相(xiàng)反。例如,很多人都通过创建标签数据集的工作拿到了薪酬。 像LevelApp这样的应用程序可以让(ràng)难民只需用(yòng)手机标记自己(jǐ)的数(shù)据就可以赚到钱(qián)。Harmon则(zé)更进(jìn)一(yī)步:他们甚至(zhì)为难民(mín)营中(zhōng)的移民提供设(shè)备,以便(biàn)这些(xiē)人可以做出贡献并以此(cǐ)谋生。 除了数据标签之外,整个行业都是通过新的AI技术(shù)创建的。我们(men)能够做到几年(nián)前无法想象的事情(qíng),比如自动驾驶汽车或新药研发。 更多与ML相关的计算将在边缘领域进行 Pipeline的后期阶段通常通(tōng)过降(jiàng)采样(yàng)或其他方式降低信号的保真(zhēn)度。另一(yī)方面,随着AI模型变得越来越复杂,它们在数据更多(duō)的情(qíng)况下表现得更好。将AI组件(jiàn)移近数据、靠近边(biān)缘,是否会有意义吗? 举一个简(jiǎn)单(dān)的例子:想象一个高分辨率的摄像机,可以每秒30千兆次的速度生成高质量的视频。处理该视频的计算机视觉模型在服务器上(shàng)运行。摄像机将视频流式传输到服务器,但上行带宽有限,因此视(shì)频会缩小(xiǎo)并被高度压缩。为何不将视觉模型(xíng)移动到相机并使用原始视频流呢(ne)? 与此同时,多个障碍总是存在(zài),它们(men)主要(yào)是:边缘设备上(shàng)可用的(de)计算能力的数量和管理的复杂性(例如将(jiāng)更新的模(mó)型推向边缘(yuán))。专用硬件(如Google的Edge TPU、Apple的神经(jīng)引(yǐn)擎等)、更高效的模(mó)型和优化软件的出现,让计(jì)算的局限(xiàn)性逐渐消失。通过(guò)改进ML框架和工具,管理复杂性问题不(bú)断得到(dào)解决。 整合AI基础架(jià)构空间(jiān) 前几(jǐ)年人工智能基础设施相关(guān)活(huó)动层出(chū)不穷:盛大的(de)公告、巨额的多轮融资(zī)和厚重的承(chéng)诺。2018年(nián),这个领域似乎降温了。虽(suī)然仍然有很多(duō)新的(de)进步,但大部分贡(gòng)献都(dōu)是由现有大型玩家做(zuò)出的。 一个可能(néng)的解释(shì)也许是我们对AI系统的理(lǐ)想基础设施的理解还(hái)不够(gòu)成(chéng)熟。由(yóu)于(yú)问题很(hěn)复杂,需要长(zhǎng)期、持久、专注而且财力雄厚(hòu)的努力,才(cái)能(néng)产(chǎn)生可行的解决方案——这(zhè)是初创公司和小公(gōng)司所不擅(shàn)长的。如(rú)果一家初(chū)创公司“解(jiě)决(jué)”了AI的问题,那绝对会让人惊奇不已。 另一方面,ML基础设施工程师却(què)很少见。对于大(dà)公司来说,一个仅有几名员工、挣(zhèng)扎(zhā)求生(shēng)的创业公司显然是很有价值的并购目标(biāo)。这个行业(yè)中(zhōng)至少(shǎo)有几(jǐ)个玩家是为了胜(shèng)利在不断(duàn)奋斗的,它们同时建立了内部和外部工具。例如,对(duì)于AWS和(hé)Google Cloud而言,AI基础设施服务是一个主要卖点。 综(zōng)上可以预测,未来在这个领域会出现一(yī)个整合(hé)多个玩家的垄断者(zhě)。 更多定制硬(yìng)件 至少对于CPU而言,摩(mó)尔定律已(yǐ)经失效了,并且这一事实已经存在很多(duō)年了。GPU很快就会遭(zāo)受(shòu)类似的命运。虽然我(wǒ)们的模型变得越(yuè)来越高效(xiào),但为了解决(jué)一些(xiē)更高级的(de)问题(tí),我(wǒ)们需要用到更多的计算能(néng)力。这可以通过分(fèn)布式训(xùn)练来解决,但它自身(shēn)也有局限。 此外,如果(guǒ)你想在(zài)资源受限的设备上运行一些较大的模型,分布(bù)式训练会变得毫无用处。进(jìn)入自定(dìng)义AI加速器。根据(jù)你想要的或可以实现的自定(dìng)义方(fāng)式,可(kě)以节省一个数量级的功耗、成本或潜在消耗。 在某(mǒu)种程(chéng)度(dù)上,即使是Nvidia的Tensor Cores也已经投身于这一趋势。如果没有通用硬件的话,我们会(huì)看到更多的案例。 减(jiǎn)少(shǎo)对训练数据(jù)的依赖 标记数据(jù)通常很昂贵,或者(zhě)不可用(yòng),也可能(néng)二者兼有(yǒu)。这一规(guī)则几乎没有例外。开(kāi)放的高质量数据集,如MNIST、ImageNet、COCO、Netflix奖和(hé)IMDB评论,都是令人(rén)难以置信的创新源泉。但是许多问题并没有可供使(shǐ)用的相应数据(jù)集(jí)。研究人员不(bú)可能自己去建立数据集(jí),而可提供赞(zàn)助或发(fā)布数据集的大公司却并不着急:他们正在构建庞大(dà)的(de)数据(jù)集,但(dàn)不(bú)让外人靠近。 那么,一个小型独立(lì)实体,如创业(yè)公司(sī)或(huò)大学研究小组,如何为那(nà)些困难的(de)问(wèn)题提供有趣的(de)解决方案呢?构建对(duì)监督信号依赖性越来越小,但对未标记和非结构化数据(廉价传感器(qì)的互联(lián)和增多使(shǐ)得这类数(shù)据变(biàn)得很丰富(fù))依赖(lài)性越来越大的系统就可以实(shí)现这一点(diǎn)。这在一定程度上解释了(le)人们(men)对GAN、转移和强化学习的兴趣激增的原因:所有这(zhè)些技术都需要(yào)较(jiào)少(或根本不需要)对训练数据集的投(tóu)资。 所以这一切(qiē)仅仅是(shì)个泡沫(mò)? 这(zhè)一行业已进入热门人工智能(néng)“盛夏”的第七年。这(zhè)段(duàn)时(shí)间内,大量的研究项目(mù)、学术(shù)资助(zhù)、风险投资、媒体关注和代码行都涌(yǒng)入了这个领域。 但人们有理由指(zhǐ)出,人工智能所做出的大部分承诺仍然还未兑现:他(tā)们最近优步打车的(de)行程依然是人(rén)类驾(jià)驶员在开车;目(mù)前依然没有出现早上能做煎蛋(dàn)的实用机器人。我甚(shèn)至不得(dé)不自己绑(bǎng)鞋带(dài),真是(shì)可悲至极! 然而(ér),无数研究生和软件(jiàn)工(gōng)程师的努力并非徒劳。似乎每家(jiā)大公司都已经十分(fèn)依赖人工智能,或者在(zài)未来实施此类计划。AI的艺术大行其道(dào)。自动驾驶(shǐ)汽车虽(suī)然尚未出(chū)现(xiàn),但它们(men)很快就会诞生了。 2018年,美国(guó)在人工(gōng)智能领域发展(zhǎn)迅速,中国(guó)也不(bú)遑(huáng)多让。这个趋势(shì)从近(jìn)期百(bǎi)度和BOSS直聘联合发布的(de)《2018年中国人工(gōng)智能ABC人才发展报告》中就可窥一斑。 |